A Generative Entity-Mention Model for Linking Entities with Knowledge Base
一.主要方法
提出了一种生成概率模型,叫做entity-mention model.
Explanation:
In our model, each name mention to be linked is modeled as a sample generated through a three-step generative story, and the entity knowledge is encoded in the distribution of entities in document P(e), the distribution of possible names of a specific entity P(s|e), and the distribution of possible contexts of a specific entity P(c|e). To find the referent entity of a name mention, our method combines the evidences from all the three distributions P(e), P(s|e) and P(c|e).
The P(e), P(s|e) and P(c|e) are respectively called the entity popularity model, the entity name model and the entity context model
二.相关介绍
建模
Given a set of name mentions M = {m1, m2, …, mk} contained in documents and a knowledge base KB containing a set of entities E = {e1, e2, …, en}, an entity linking system is a function s : M ® E which links these name mentions to their referent entities in KB.
Popularity Knowledge
实体的流行度知识告诉我们一个实体出现在文档中的可能性
Name Knowledge
名称知识告诉我们实体的可能名称,以及名称引用特定实体的可能性。
Context Knowledge
上下文知识告诉我们一个实体出现在特定上下文中的可能性。
三.The Generative Entity-Mention Model for Entity Linking
Explanation
- 首先,该模型根据P(e)中实体的分布情况,从给定知识库中选择提及名称的引用实体e。
- 其次,该模型根据被引用实体P(s|e)的可能名称的分布情况输出所述名称的名称s。
- 最后,模型根据被引用实体P(c|e)可能的上下文分布输出所提到的名称的上下文c。
model
The probability of a name mention m (its context is c and its name is s) referring to a specific entity e can be expressed as the following formula (here assume that s and c are independent):
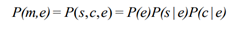
Give a name mention m, to perform entity linking, we need to find the entity e which maximizes the probability P(e|m).

Candidate Selection
building a name-to-entity dictionary using the redirect links, disambiguation pages, anchor texts of Wikipedia, then the candidate entities of a name mention are selected by finding its name’s corresponding entry in the dictionary
四.Model Estimation
Entity Popularity Model
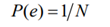 ----》
----》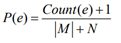
where Count(e) is the count of the name mentions whose referent entity is e, and the |M| is the total name mention size.
Entity Name Model
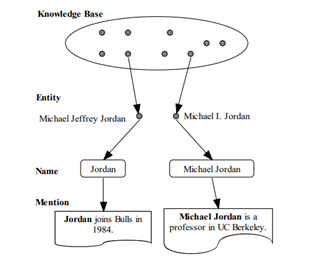
比如,我们希望 P(Michael Jordan|Michael Jeffrey Jordan) 高,,P(MJ|Michael Jeffrey Jordan) 也高。 P(Michael I. Jordan|Michael Jeffrey Jordan) 应该是0.
因此,名称模型可以通过首先从数据集中收集所有(实体、名称)对来估计。
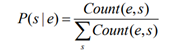
缺点:它不能正确地处理一个不可见的实体或一个不可见的名称。
Eg: “MJ”在Wikipedia指的并不是Michael Jeffrey Jordan, 这个the name model 将不能识别 “MJ” 就是Michael Jeffrey Jordan.
↓
1) It is retained (translated into itself);
2) It is translated into its acronym;
3) It is omitted(translated into the word NULL);
4) It is translated into another word (misspelling or alias).

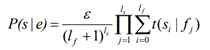
wheree is a normalization factor, f is the full name of entity e, lf is the length of f, ls is the length of the name s, si the i th word of s, fj is the j th word of f and t(si|fj) is the lexical translation probability which indicates the probability of a word fj in the full name will be written as si in the output name.
Entity Context Model
例如:
C1: __wins NBA MVP.
C2: __is a researcher in machine learning
P(C1|Michael Jeffrey Jordan)应该很高,因为NBA球员迈克尔杰弗里乔丹经常出现在C1和P(C2|Michael Jeffrey Jordan)应该是非常低的,因为他很少出现在C2.
a context c containing n terms t1,t2…tn (term: a word; a named entity; a Wikipedia concept) ,the entity context model estimates the probability P(c|e) as
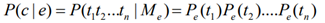
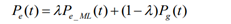
where Pg(t) is a general language model which is estimated using the whole Wikipedia data, and the optimal value of λ is set to 0.2
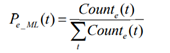
where Counte(t) is the frequency of occurrences of a term t in the contexts of the name mentions whose referent entity is e
The NIL Entity Problem
假设:“如果一个名字被提到是指一个特定的实体,那么这个名字被提到的概率是由特定实体的模型产生的,应该显著高于由一般语言模型产生的概率
1. add a pseudo entity, the NIL entity, into the knowledge base
2. the probability of a name mention is generated by the NIL entity is higher than all other entities in Knowledge base, we link the name mention to the NIL entity.
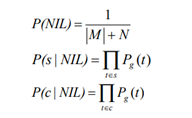
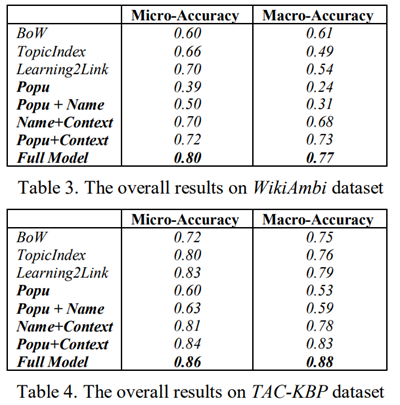
五.Experiments